Open Source ElasticSearch Alternatives
A curated collection of the 16 best open source alternatives to ElasticSearch.
The best open source alternative to ElasticSearch is Meilisearch. If that doesn't suit you, we've compiled a ranked list of other open source ElasticSearch alternatives to help you find a suitable replacement. Other interesting open source alternatives to ElasticSearch are: Milvus, Onyx, Qdrant, and Chroma.
ElasticSearch alternatives are mainly Search Engines but may also be Vector Databases or AI Search Tools. Browse these if you want a narrower list of alternatives or looking for a specific functionality of ElasticSearch.
Written by Piotr Kulpinski


A powerful, fast, and easy-to-use search engine that delivers instant and relevant results for your websites and applications.

Meilisearch is an open-source search engine that revolutionizes the way you implement search functionality in your projects. With its lightning-fast performance and intuitive features, Meilisearch stands out as the go-to solution for developers seeking efficient and accurate search capabilities.
Key benefits of Meilisearch include:
- Blazing Speed: Experience millisecond search times, even with large datasets, ensuring a smooth user experience.
- Typo Tolerance: Built-in typo tolerance helps users find what they're looking for, even if they make spelling mistakes.
- Customizable Relevance: Fine-tune search results to match your specific needs with customizable ranking rules.
- Multi-language Support: Seamlessly handle searches in various languages, making it ideal for global applications.
- Easy Integration: With SDKs for popular programming languages, integrating Meilisearch into your project is a breeze.
- RESTful API: A simple and powerful API allows for easy communication between your application and Meilisearch.
- Faceted Search: Implement advanced filtering options to help users narrow down their search results effortlessly.
- Scalability: Designed to handle growing datasets, Meilisearch scales with your application's needs.
Whether you're building an e-commerce platform, a content management system, or any application requiring robust search functionality, Meilisearch provides the tools you need to create an exceptional search experience for your users.

CodeRabbit
The leading AI Code Review platform. Ship better quality code in 50% less time, with 90% fewer bugs.
Try it for free
Open-source vector database optimized for similarity search, scaling to billions of vectors with minimal performance loss

Milvus is an open-source vector database built specifically for GenAI applications. It offers high-performance similarity search capabilities and seamless scalability to handle billions of vectors.
Key features:
- Easy installation: Get started quickly with a simple pip install
- Blazing-fast searches: Perform high-speed similarity searches on massive vector datasets
- Elastic scalability: Scale effortlessly to tens of billions of vectors with minimal performance impact
- Flexible deployment: Choose from lightweight Milvus Lite for prototyping, robust Standalone for production, or fully distributed deployment for enterprise-scale workloads
- Rich ecosystem: Integrates smoothly with popular AI tools like LangChain, LlamaIndex, OpenAI, and more
- Advanced capabilities: Supports metadata filtering, hybrid search, multi-vector queries and other powerful features
Milvus empowers developers to build robust and scalable GenAI applications across various domains including image retrieval, recommendation systems, and semantic search. Its focus on performance, scalability and ease-of-use makes it a top choice for vector similarity search at any scale.

An open-source platform that connects to 40+ apps to provide intelligent search and AI assistance across all company information
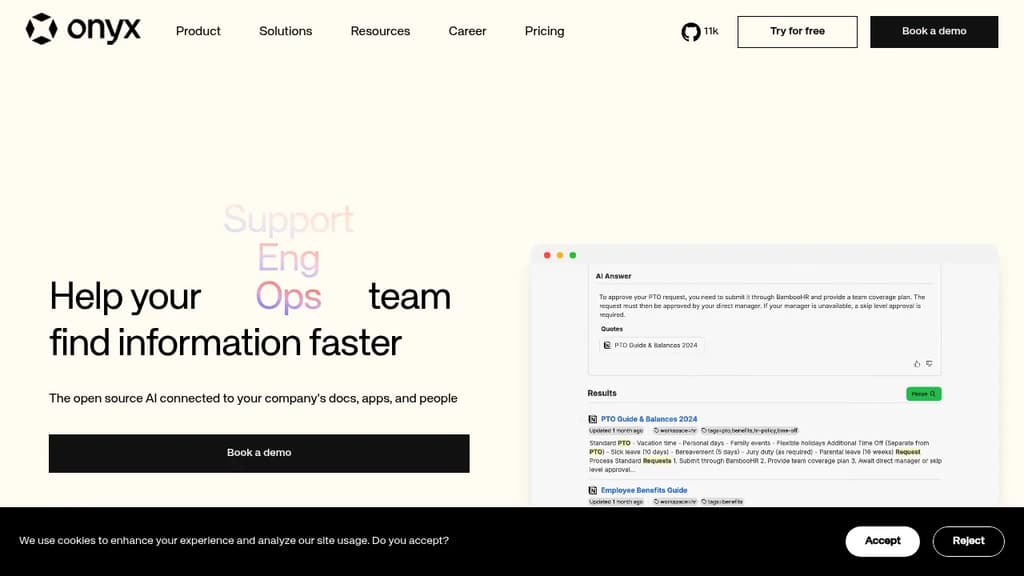
Onyx is a powerful open-source enterprise search platform that transforms how teams find and access information. With seamless integration across 40+ popular business tools like Slack, GitHub, Notion, and Google Workspace, it creates a unified search experience powered by AI.
Key features include:
- AI Workplace Search that helps teams quickly find answers across all connected apps and documents
- AI Assistant capabilities that leverage your organization's knowledge to provide contextual responses
- Developer-friendly APIs for building custom workflows and integrations
- Enterprise-grade security with document-level permissions and optional air-gapped deployment
- Model flexibility allowing you to choose or self-host your preferred AI models
The platform is designed to be highly extensible with modular architecture, making it easy to customize and adapt to your specific needs while maintaining complete control over your data.

Qdrant is an open-source vector database that provides high-performance similarity search for AI and machine learning applications.

Qdrant is a powerful open-source vector database designed for high-performance similarity search in AI and machine learning applications. Built with Rust for unmatched speed and reliability, Qdrant excels at handling billions of high-dimensional vectors.
Key features:
- Cloud-native scalability: Easily scale vertically and horizontally with zero-downtime upgrades
- Flexible deployment: Quick setup with Docker for local testing or cloud deployment
- Cost-efficient storage: Built-in compression options to dramatically reduce memory usage
- Advanced search capabilities: Supports semantic search and handles multimodal data efficiently
- Easy integration: Lean API for seamless integration with existing systems
Qdrant is ideal for powering recommendation systems, advanced search applications, and retrieval augmented generation (RAG) workflows. Its ability to quickly process complex queries on large datasets makes it suitable for a wide range of AI-driven use cases.
Real-world impact: Trusted by leading companies like Bosch, Cognizant, and Bayer for enterprise-scale AI applications. Qdrant consistently outperforms alternatives in ease of use, performance, and value.
Whether you're building a cutting-edge AI product or enhancing existing applications with vector search capabilities, Qdrant provides the speed, scalability, and flexibility needed to bring your ideas to life.

Open-source vector database designed for AI applications. Store, search, and retrieve embeddings with semantic similarity matching and metadata filtering.
Chroma is a powerful open-source vector database specifically built for AI applications that need efficient storage and retrieval of embeddings. Perfect for developers building RAG (Retrieval-Augmented Generation) systems, semantic search engines, and AI-powered applications.
Key features include:
- Vector storage and similarity search - Store high-dimensional embeddings and perform fast semantic similarity queries
- Metadata filtering - Combine vector search with traditional filtering for precise results
- Multiple embedding models - Support for OpenAI, Sentence Transformers, and custom embedding functions
- Flexible deployment - Run locally, in-memory, or deploy to production with persistent storage
- Simple Python API - Get started quickly with intuitive methods for adding, querying, and managing collections
- Language integrations - Native support for Python and JavaScript with additional language bindings
Whether you're building a chatbot that needs to search through documents, creating a recommendation system, or developing any AI application requiring semantic search capabilities, Chroma provides the foundation you need with minimal setup and maximum flexibility.

Open-source search solution offering blazing speed, typo tolerance, and effortless scalability for developers and businesses.

Typesense is a modern, open-source search engine designed to deliver exceptional performance and developer-friendly experiences. With its lightning-fast search capabilities and innovative features, Typesense empowers developers to create powerful search applications with ease.
Key benefits of Typesense include:
- Blazing Fast: Engineered for speed, Typesense returns results in less than 50ms, ensuring a smooth and responsive search experience for users.
- Typo Tolerance: Built-in typo tolerance automatically handles misspellings and typos, improving search accuracy and user satisfaction.
- Simple Setup: Get up and running in minutes with a single binary and minimal configuration, reducing development time and complexity.
- Language Agnostic: Seamlessly integrate Typesense with your preferred programming language using our wide range of API clients.
- Highly Scalable: Easily scale your search infrastructure horizontally to handle growing data volumes and user traffic.
- Rich Features: Enjoy out-of-the-box support for faceting, filtering, sorting, and geosearch capabilities to enhance your search functionality.
- Cloud or Self-Hosted: Choose between Typesense Cloud for hassle-free managed hosting or self-host on your own infrastructure for complete control.
Typesense combines the power of advanced search algorithms with a user-friendly interface, making it an ideal choice for developers, startups, and enterprises alike. Experience the future of search technology and unlock the full potential of your data with Typesense.

Stellar Hosted
Managed Open Source software hosting in the EU: secure, compliant, fast.
Start using Open Source today
Monitor logs, metrics, and traces with an open-source observability platform. Achieve petabyte scale with 140x lower storage costs and high performance.

OpenObserve is a comprehensive, open-source observability platform designed for logs, metrics, and traces. It offers a modern, scalable architecture built for high performance and significant cost savings. The platform's primary advantage is its efficiency, providing up to 140x lower storage costs when compared to alternatives like Elasticsearch. This is achieved through high data compression and a columnar storage format.
Key features include:
- High Performance: Built in Rust and utilizing the DataFusion query engine for rapid data analysis, even at petabyte scale.
- Scalability: A stateless architecture allows for easy horizontal scaling to handle enterprise-level workloads.
- Cost-Effectiveness: Drastically reduces telemetry costs with high compression and the ability to use your own storage buckets like S3, GCS, and Azure Blob.
- Open Standards: Fully compatible with OpenTelemetry, ensuring seamless integration with existing tools and workflows.

Community-driven, Apache 2.0-licensed search and analytics suite for ingesting, searching, visualizing, and analyzing data at scale with AI/ML capabilities.

OpenSearch is a comprehensive open-source search and analytics platform that transforms how organizations handle unstructured data at scale. Built on Apache 2.0 licensing, this community-driven solution offers enterprise-grade capabilities without vendor lock-in.
The platform excels in four key areas: AI/ML-powered application development, intelligent search solutions, application and infrastructure observability, and real-time security threat detection. Its integrated architecture allows seamless data ingestion, search, visualization, and analysis across diverse use cases.
Key advantages include:
- Complete freedom with open-source licensing and community governance
- Scalable architecture designed for enterprise workloads
- AI/ML integration for advanced analytics and intelligent applications
- Real-time capabilities for monitoring and security use cases
- Comprehensive toolset with built-in visualization and analytics components
The OpenSearch Software Foundation, established as a Linux Foundation project in 2024, ensures long-term sustainability and community-driven development. With active global conferences and a vibrant contributor ecosystem, OpenSearch continues evolving to meet modern data challenges.
Whether you're building search applications, monitoring infrastructure, or analyzing security data, OpenSearch provides the flexibility and power needed for mission-critical deployments.

Logstash is a free and open server-side data processing pipeline that ingests data from multiple sources, transforms it, and sends it to your desired destination.

Logstash is a powerful data processing pipeline that allows you to collect, transform, and ship data from various sources to multiple destinations. Here are some key features and benefits:
-
Versatile Input Support:
- Ingest data from a wide range of sources, including logs, metrics, web applications, data stores, and AWS services.
- Supports continuous, streaming data ingestion.
-
Powerful Data Transformation:
- Parse and structure unstructured data using grok patterns.
- Derive additional information, such as geolocations from IP addresses.
- Anonymize or exclude sensitive data for compliance and security.
- Transform data into a common format for easier analysis.
-
Flexible Output Options:
- Send processed data to various destinations, with Elasticsearch being a primary output.
- Route data to multiple outputs simultaneously for different use cases.
-
Extensibility:
- Pluggable framework with over 200 plugins available.
- Easy-to-build custom plugins for specific needs.
-
Reliability and Security:
- Guarantees at-least-once delivery with persistent queues.
- Dead letter queues for handling processing failures.
- Ability to secure ingest pipelines.
-
Monitoring and Management:
- Built-in monitoring features for observing performance and availability.
- Pipeline Viewer for understanding and optimizing data flows.
- Centralized management through a user-friendly UI.
-
Elastic Stack Integration:
- Seamless integration with other Elastic Stack components like Elasticsearch and Kibana.
- Pre-built modules for quick setup with popular data sources.
Logstash is an essential tool for organizations looking to centralize and process their data efficiently, making it ready for analysis and visualization in platforms like Elasticsearch and Kibana.

High-performance search engine designed for big data, offering scalability, real-time indexing, and cost-effective operations.

Quickwit is a revolutionary search engine built to handle massive datasets with unparalleled speed and efficiency. It combines the power of distributed systems with innovative indexing techniques to deliver lightning-fast search capabilities for modern data-intensive applications.
Key benefits of Quickwit include:
- Scalability: Easily handle terabytes to petabytes of data without compromising performance.
- Real-time indexing: Update your search index in milliseconds, ensuring your data is always up-to-date.
- Cost-effective: Optimize resource usage and reduce operational costs with efficient data storage and processing.
- Cloud-native: Seamlessly integrate with cloud environments for flexible deployment and management.
- Full-text search: Powerful querying capabilities for precise and relevant results.
- Time-series optimized: Specially designed for time-series data, making it ideal for log analytics and observability.
- Open-source: Benefit from community-driven development and transparency.
Quickwit's architecture separates compute and storage, allowing for independent scaling and cost optimization. Its append-only index design ensures data integrity and enables efficient updates. With support for various data formats and integrations with popular tools, Quickwit fits seamlessly into existing data pipelines and analytics workflows.
Experience the future of big data search with Quickwit – where speed, scale, and simplicity converge.

Open source search database delivering 2.83x faster performance than Elasticsearch. Features vector search, SQL interface, and full-text capabilities.
Manticore Search is a high-performance open source search database designed to deliver exceptional speed and efficiency for modern applications. Built as a powerful Elasticsearch alternative, it consistently outperforms competitors with 2.83x faster performance for big data and 10.09x faster log analytics processing.
Key Features:
- Vector and semantic search capabilities for AI-powered applications
- SQL interface alongside full-text search functionality
- Resource efficient - runs smoothly on minimal hardware (1 core, 1GB RAM)
- Multiple API support - JSON, MySQL protocol, HTTP, and native clients
- Easy integration with popular tools like Kibana for log analysis
The database excels in cost-effective operations while maintaining enterprise-grade performance. Whether you're processing billions of documents or handling real-time search queries, Manticore Search provides the speed and reliability your applications demand.
Developer-friendly setup with comprehensive language support including Python, PHP, JavaScript, Go, Java, and Rust. Get started with just a few lines of code and experience sub-millisecond response times for your search workloads.
100% open source under GPL license with professional consulting services available for enterprise deployments and custom feature development.

Docmost
Open-source wiki software with real-time collaboration, diagrams, AI, SSO, RBAC permissions and more.
Get started now
Blend full-text and semantic search for unlimited queries across 300 global locations. Get precise answers and matches at a flat rate, no matter your search volume.
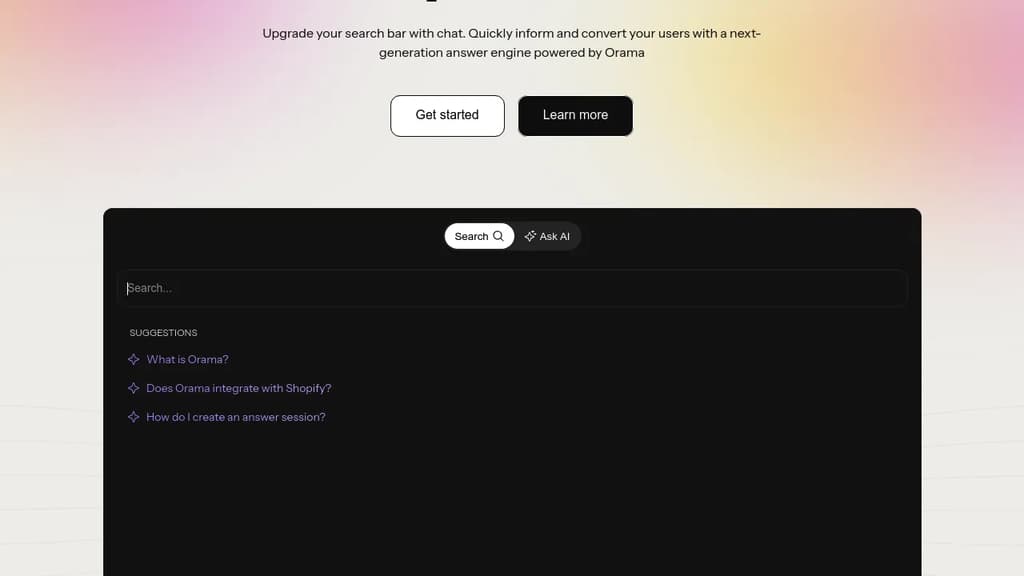
Orama is an innovative search and answer engine designed to enhance product discovery and customer support. Key features include:
-
Hybrid search: Combines full-text matches and semantic search to provide accurate results even when users don't use exact keywords.
-
AI-powered answers: Generates answers from the best sources found, going beyond simple keyword matching.
-
Unlimited usage: Offers unlimited search and answers for a flat rate, making it cost-effective for businesses of all sizes.
-
Easy integration: Supports populating indexes from various sources like databases, APIs, and files. Offers plugins for popular platforms like Vitepress and Docusaurus.
-
Open-source option: Provides a self-hostable open-source version for customization and control.
-
Fast and efficient: Delivers quick results, improving user experience and satisfaction.
-
Versatile applications: Suitable for e-commerce, documentation, and customer support scenarios.
Orama stands out by offering a comprehensive solution that combines traditional search capabilities with AI-powered answers, all while maintaining a simple pricing model and the flexibility of open-source options.

Rust-built native graph-vector database combining vector similarity search and graph traversals. 10x faster development with unified architecture, sub-1ms queries.
HelixDB is a groundbreaking native graph-vector database that eliminates the need for multiple databases by unifying vector similarity search and graph traversal operations in a single, high-performance engine. Built in Rust and backed by Y Combinator and NVIDIA, it's specifically designed for AI agents, RAG systems, and applications requiring advanced contextual retrieval.
Key performance advantages:
- Vector similarity search: ~2ms average response time
- Graph traversals: Sub-1ms execution speed
- Cost reduction: Up to 50% lower operational costs by eliminating architectural complexity
- Type-safe queries: Advanced static analysis with real-time feedback and autocomplete
Developer-friendly features:
- Simple CLI installation with
curl -sSL "https://install.helix-db.com" | bash - Hybrid query traversals combining vector and graph operations seamlessly
- Comprehensive SDKs and extensive documentation
- Local deployment or managed cloud service options
Enterprise support includes:
- 24/7 expert monitoring and support
- Enterprise-grade security and compliance
- Automatic scaling for traffic spikes
- 99.99% uptime guarantee
Perfect for teams building next-generation AI applications who want to reduce database complexity while achieving industry-leading performance. The growing developer community and active support channels make it easy to get started and scale efficiently.

AI-powered search and RAG platform that connects to 100+ enterprise tools without data migration. Deploy securely on-premises with any LLM.
SWIRL transforms how enterprises access their knowledge by connecting AI directly to existing data sources without requiring expensive migrations or exposing sensitive information.
Key advantages:
- Zero data migration required - connects to 100+ enterprise platforms including SharePoint, Salesforce, Snowflake, and more
- Deploy anywhere - on-premises, private cloud, or hybrid environments with complete data isolation
- Use any LLM - works with your preferred language model, including air-gapped deployments
- Launch in minutes - no development time or complex setup required
- Maintain security - leverages existing SSO and permissions for compliance
Real enterprise impact:
- Fortune 500 pharma company saved $3M in migration costs while reducing analyst time by 20%
- Government agencies deployed secure search in classified environments
- Real estate firm reduced contract risk by finding hidden compliance issues across scattered documents
Universal search capabilities include relevancy re-ranking, real-time data access, and AI agent enablement. SWIRL eliminates the data scavenger hunt by providing instant answers from your company's information while keeping your intellectual property secure and maintaining full control over your data governance.

Trieve offers an all-in-one solution for search, recommendations, and RAG with automatic continuous improvement based on user feedback.

Trieve is an AI-first infrastructure API designed to revolutionize search, recommendations, and Retrieval-Augmented Generation (RAG) experiences. This powerful platform combines cutting-edge language models with advanced tools for fine-tuning ranking and relevance, offering a comprehensive solution for businesses looking to enhance their discovery and information retrieval processes.
Key features and benefits:
- Semantic vector search: Go beyond traditional full-text search with built-in semantic understanding.
- Hybrid search capabilities: Combine full-text search with semantic vector search for optimal results.
- Automatic continuous improvement: Leverages dozens of feedback signals to refine and enhance search quality over time.
- Sub-sentence highlighting: Pinpoint exact relevant information within search results for quick user comprehension.
- Customizable embedding models: Choose from stock models or bring your own for tailored performance.
- Self-hostable option: For organizations with sensitive data or specific performance requirements.
- Comprehensive API: Covers chunking, ingestion, search, recommendations, RAG, and even some front-end functionality.
- No-code dashboard: Easily tune and boost search results to meet specific KPIs without technical expertise.
Trieve's platform is designed to be fast, flexible, and scalable, capable of handling billion-scale search and discovery tasks. Whether you're building a new product or enhancing an existing one, Trieve provides the tools to create delightful, efficient, and intelligent search experiences that can give your business a competitive edge.
By choosing Trieve, you're not just implementing a search solution – you're future-proofing your discovery capabilities with an AI-native, end-to-end platform built for today's needs and tomorrow's innovations.

Unified platform for logs, metrics, traces and profiles with native compatibility for popular tools like OpenTelemetry, Prometheus, and Loki. No data silos, no usage limits.
A powerful observability platform that brings together logs, metrics, traces and profiles in one unified solution. Built on high-performance OLAP engines ClickHouse and DuckDB with NVMe storage, Gigapipe delivers exceptional speed and reliability.
Key advantages:
- Drop-in compatibility with OpenTelemetry, Loki, Prometheus, Tempo, Pyroscope and other popular tools
- Flat-cost pricing model with no usage limits or surprise bills
- True open source solution under AGPLv3 license
- Single platform approach eliminates data silos and reduces complexity
- Native support for thousands of compatible agents
- Query API that emulates familiar tools like Loki and Prometheus
Perfect for engineering teams and DevOps professionals who need comprehensive observability without the complexity of managing multiple tools or worrying about data volume costs. Gigapipe's polyglot approach ensures you can work with your data your way, while the unified platform enables quick correlation between different data types for faster troubleshooting and deeper insights.
 Logto
LogtoPeople are looking for alternatives to...






